人工智能行业深度报告:从Sora看多模态大模型发展
1、OpenAI发布视频生成模型Sora,视频生成能力实现大幅提升
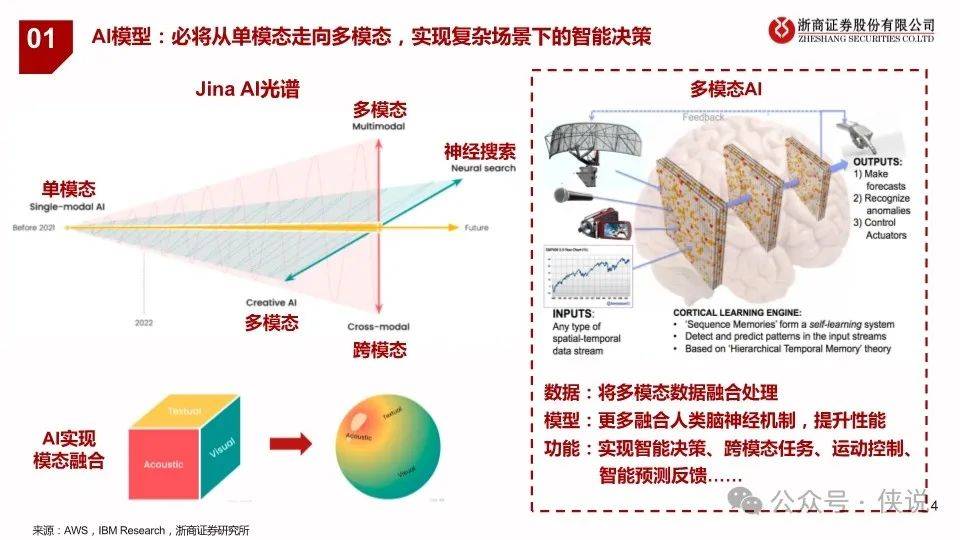
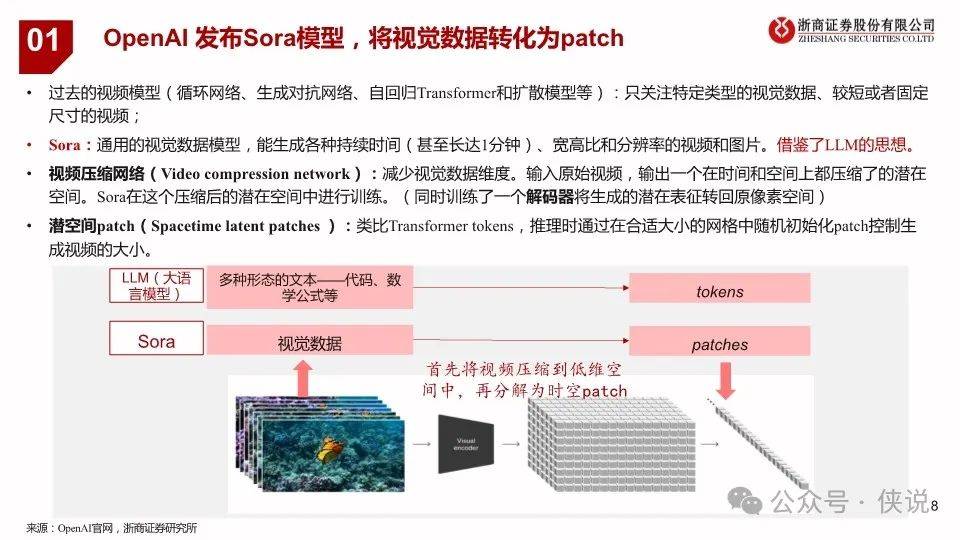
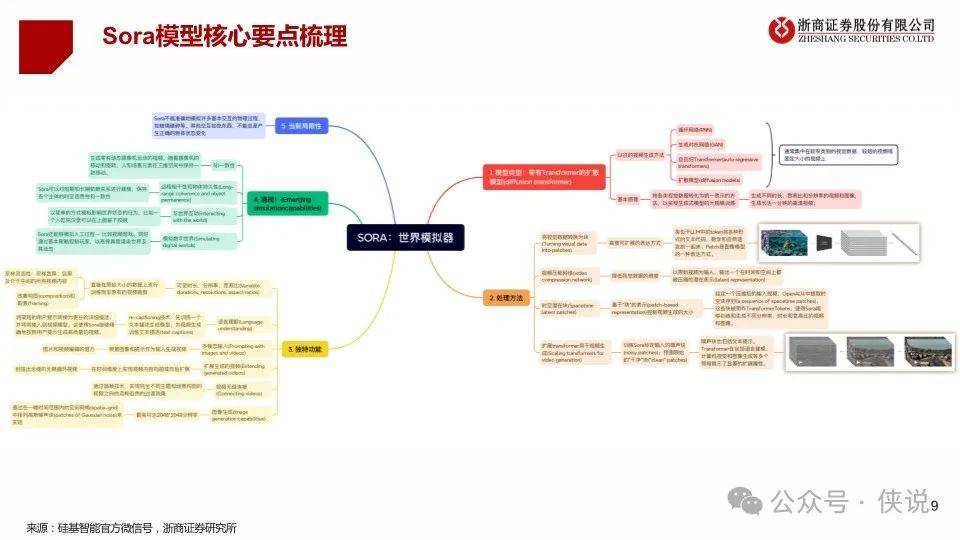
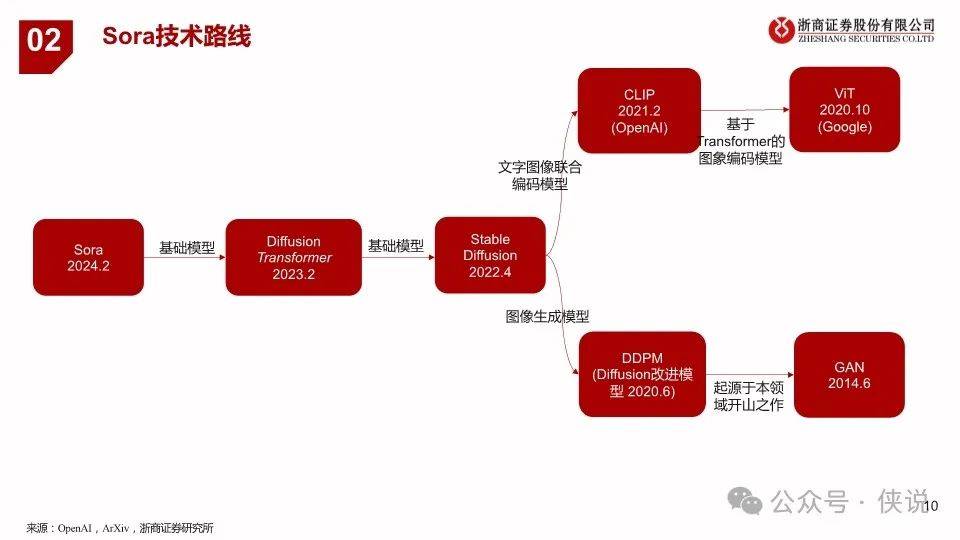
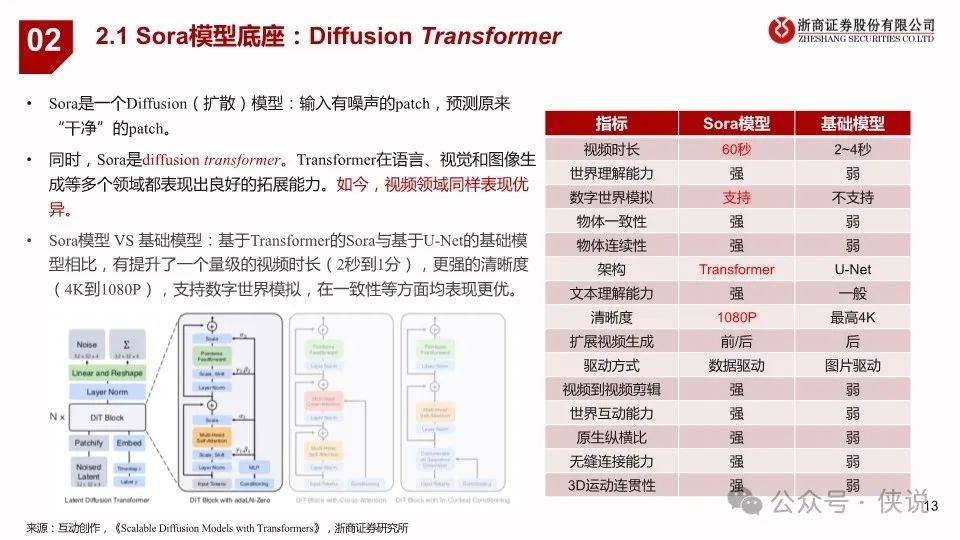
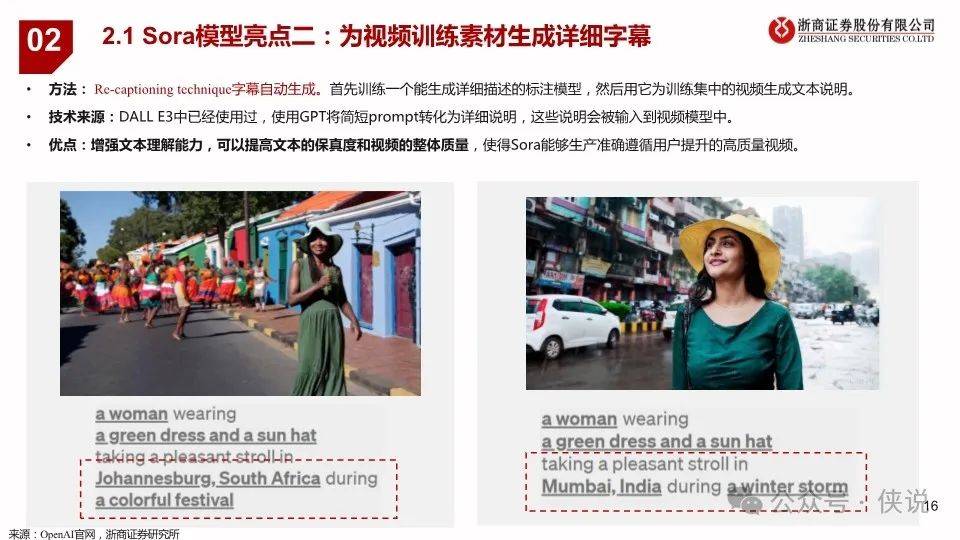
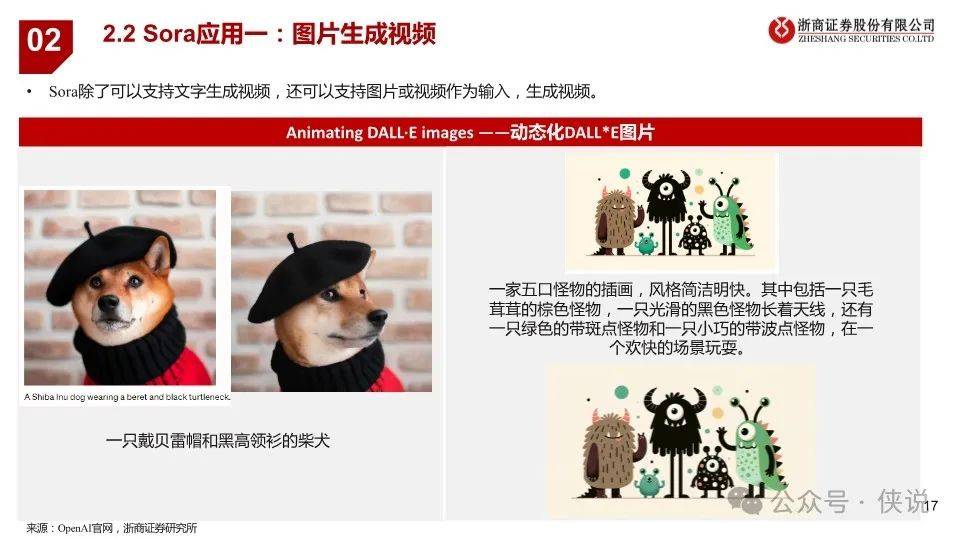
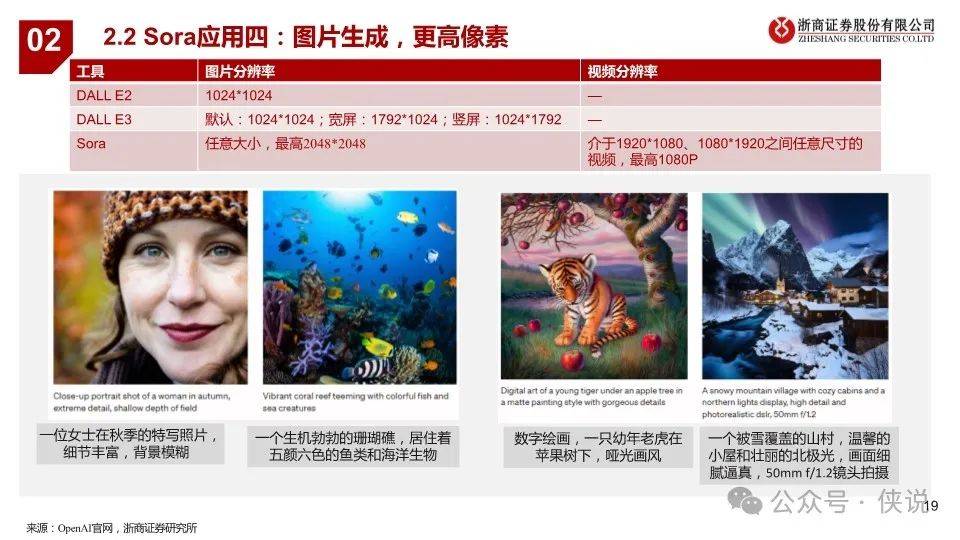
2024年2月16日,OpenAI发布视频生成模型Sora,能生成各种持续时间(甚至长达1分钟)、宽高比和分辨率的视频和图片。Sora 模型基于 Diffusion Transformer技术,采用视频压缩网络(Video compression network)、潜空间patch(Spacetime latent patches )、直接在原始大小训练(Training on data at its native size)以及重新标注技术(Re-captioning technique)技术,可以图像和视频作为输入,实现制作无缝循环视频、给静态图片添加动画、扩展视频时间线、视频到视频编辑、视频拼接等功能;
2、国内外厂商相继发力布局多模态大模型领域,2024年文生视频有望进入商业化探索哦阶段
目前除OpenAI之外,谷歌、字节跳动等厂商均已推出具备文生视频能力的多模态模型。基于对Stable Video Diffusion、谷歌W.A.L.T以及其它文生视频模型的分析,我们认为高质量数据以及底层通用大模型是文生视频能力的重要决定因素,随着Transformer架构的引入,以及3D建模领域模型的迭代,2024年文生视频有望在时间长度、画面清晰度、内容逼真程度等方面实现显著迭代,打开商业化应用空间。
3、海外已有部分文生视频商业化案例,未来有望覆盖全球千亿级视频内容生成市场
根据PR Newswire数据预测,2025年全球数字视频市场内容规模有望达到3271.9亿美元,2021-2025年CAGR超过14%。目前海外已有Synthesia、Runway等厂商在文生视频领域形成成熟商业方案,应用于企业产品介绍、操作指南、客户服务等场景。我们认为以Sora为代表的多模态模型有望显著降低视频等数字内容的创作成本,市场空间广阔。
报告节选内容如下: