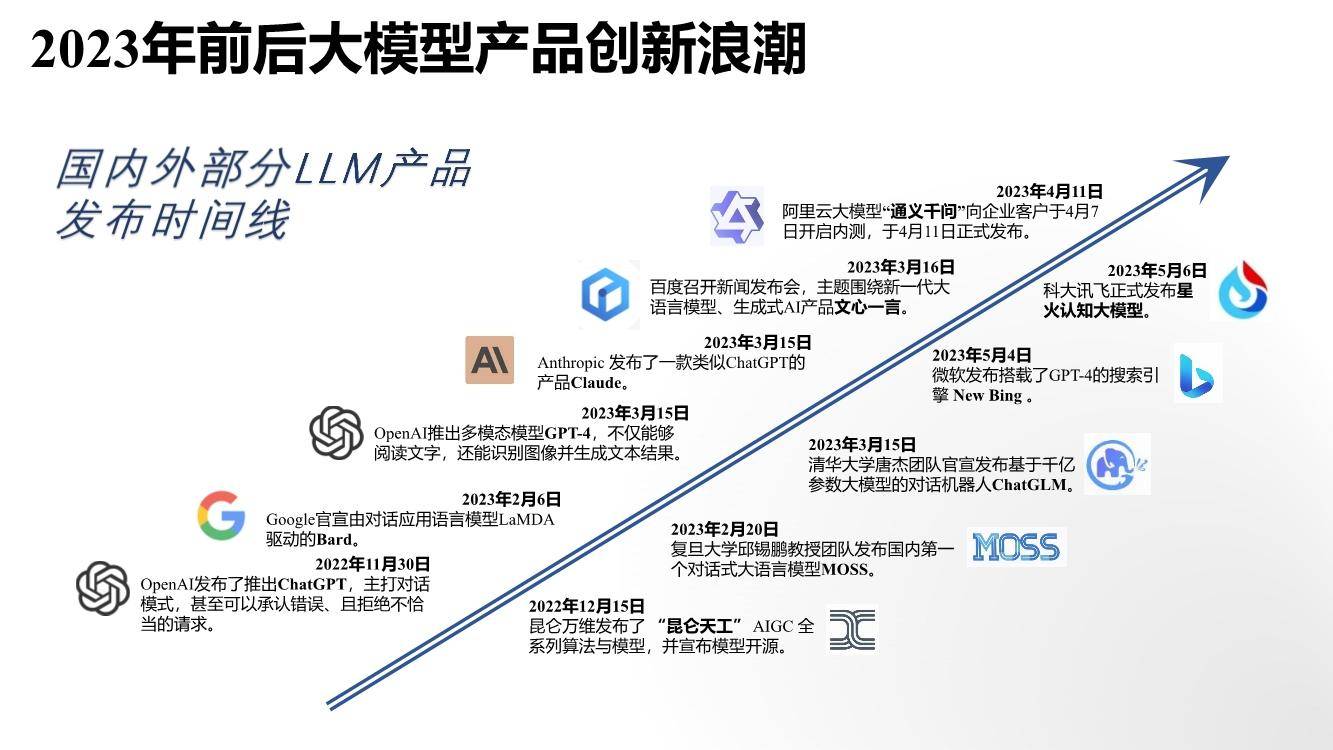
清华大学:大语言模型综合性能评估报告
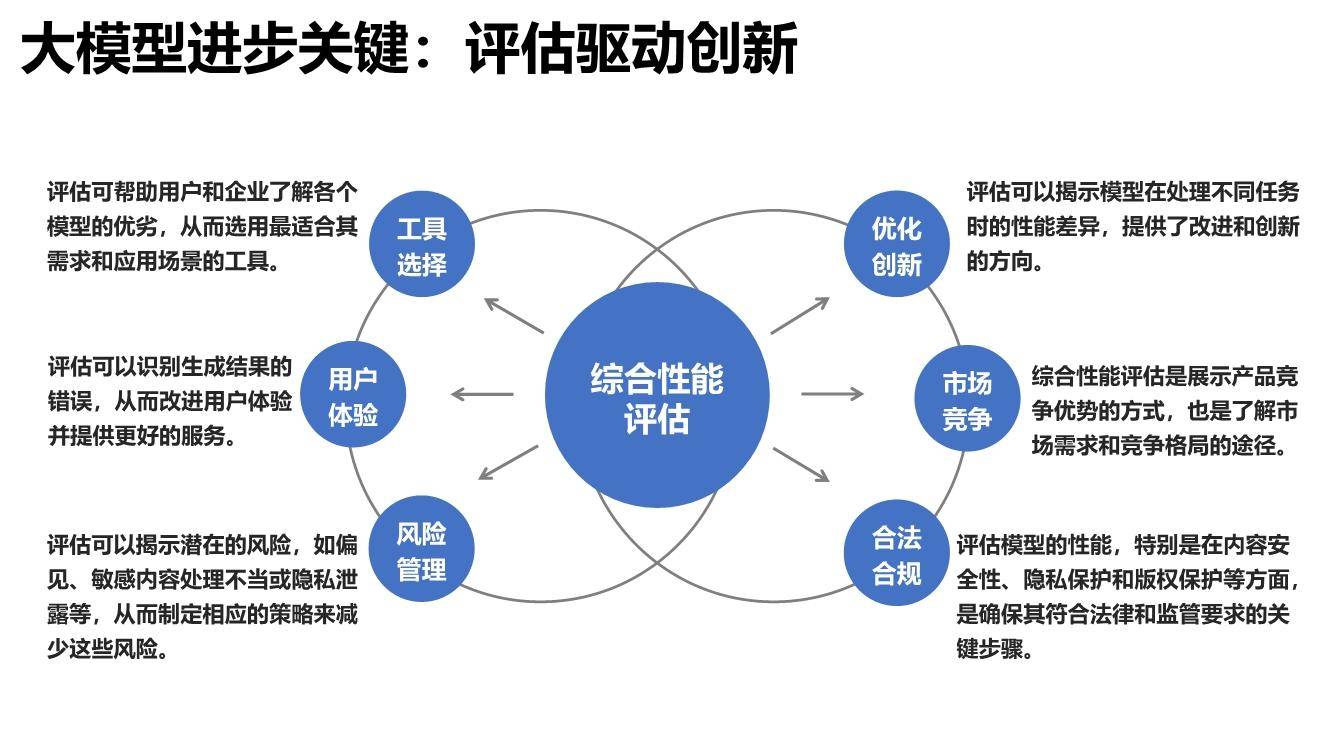
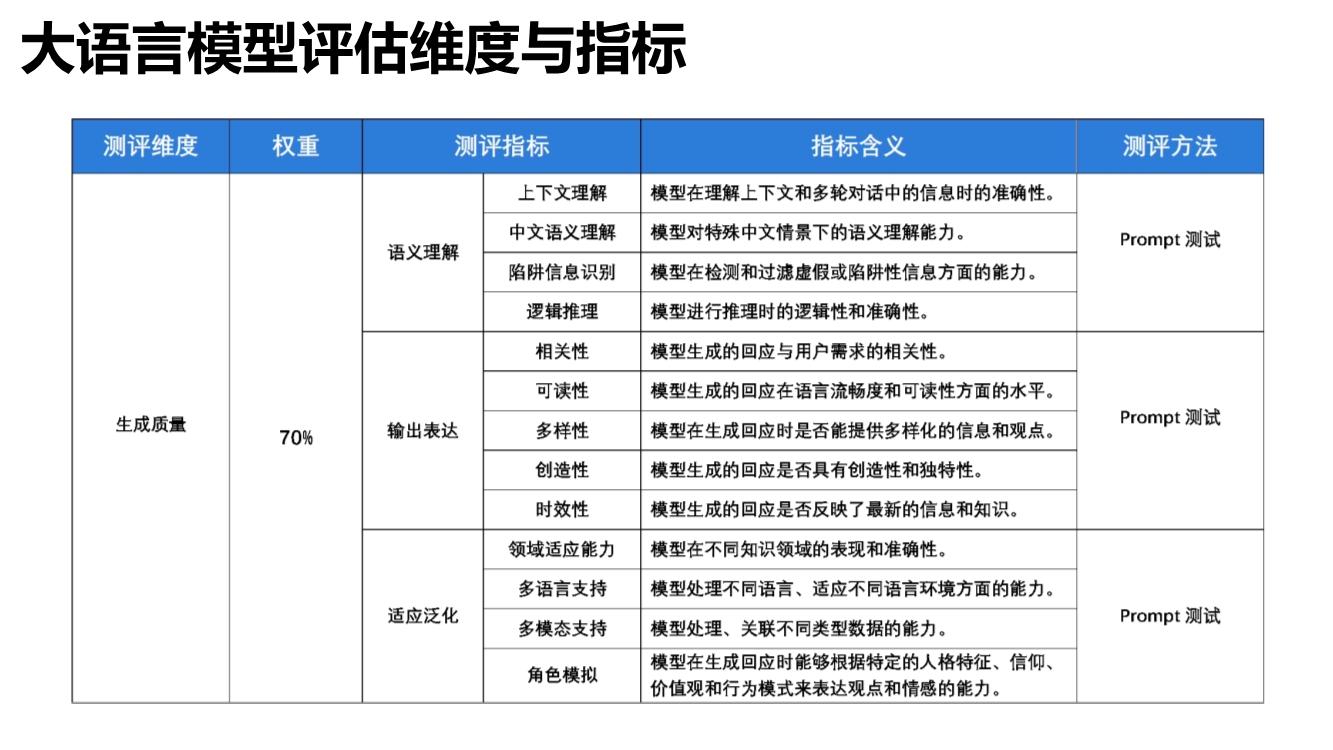
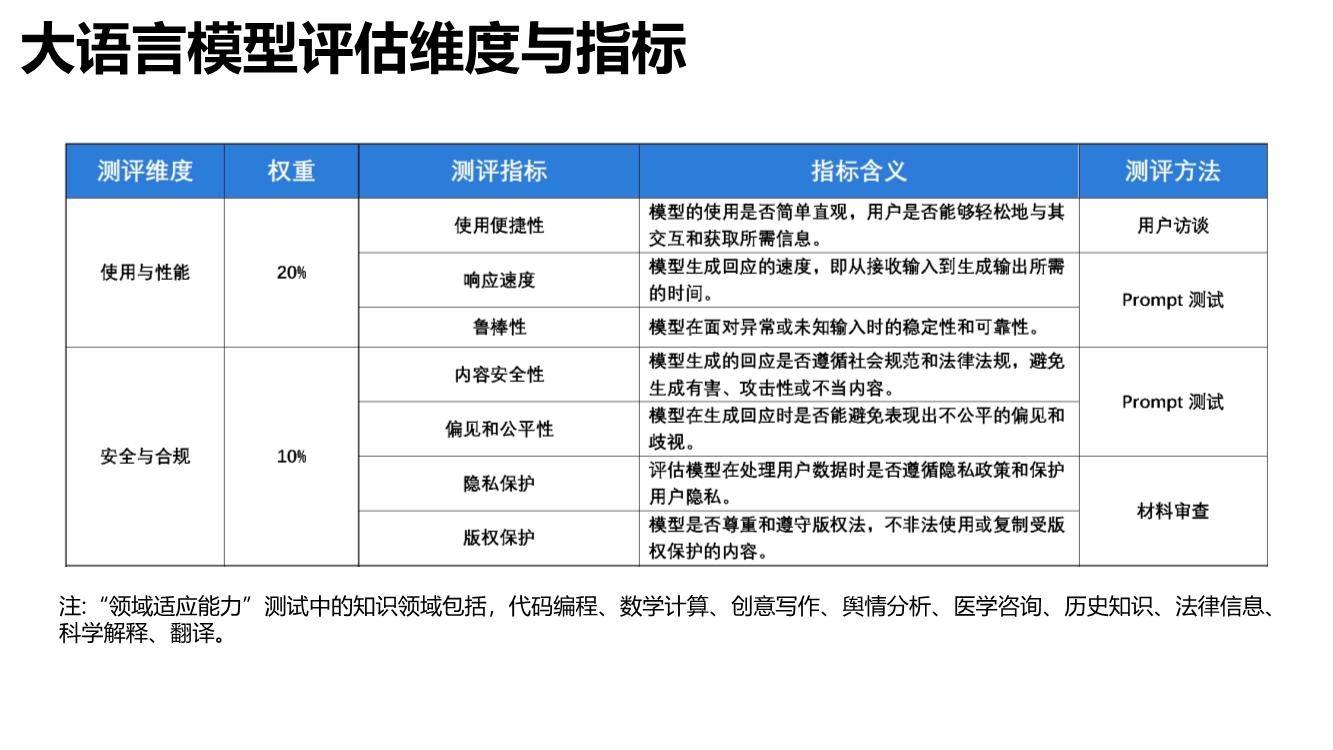
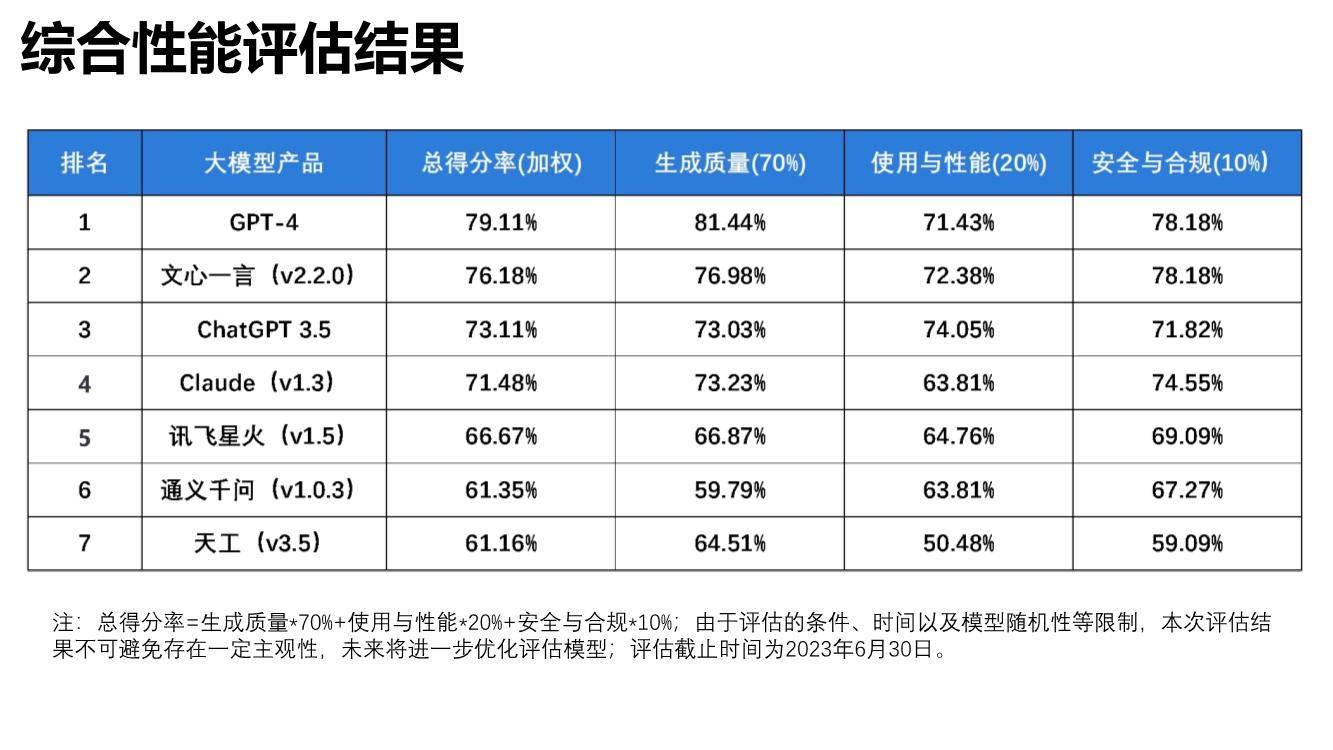
近日,清华大学新闻与传播学院发布了《大语言模型综合性能评估报告》,报告本次评估选取了GPT-4、ChatGPT 3.5、文心一言、通义千问、讯飞星火、Claude、天工7个大语言模型,围绕生成质量、使用与性能、安全与合规三大维度,全面考察大语言模型上下文理解、中文语义理解、误导信息识别、逻辑推理、内容安全性、隐私保护等20项指标。
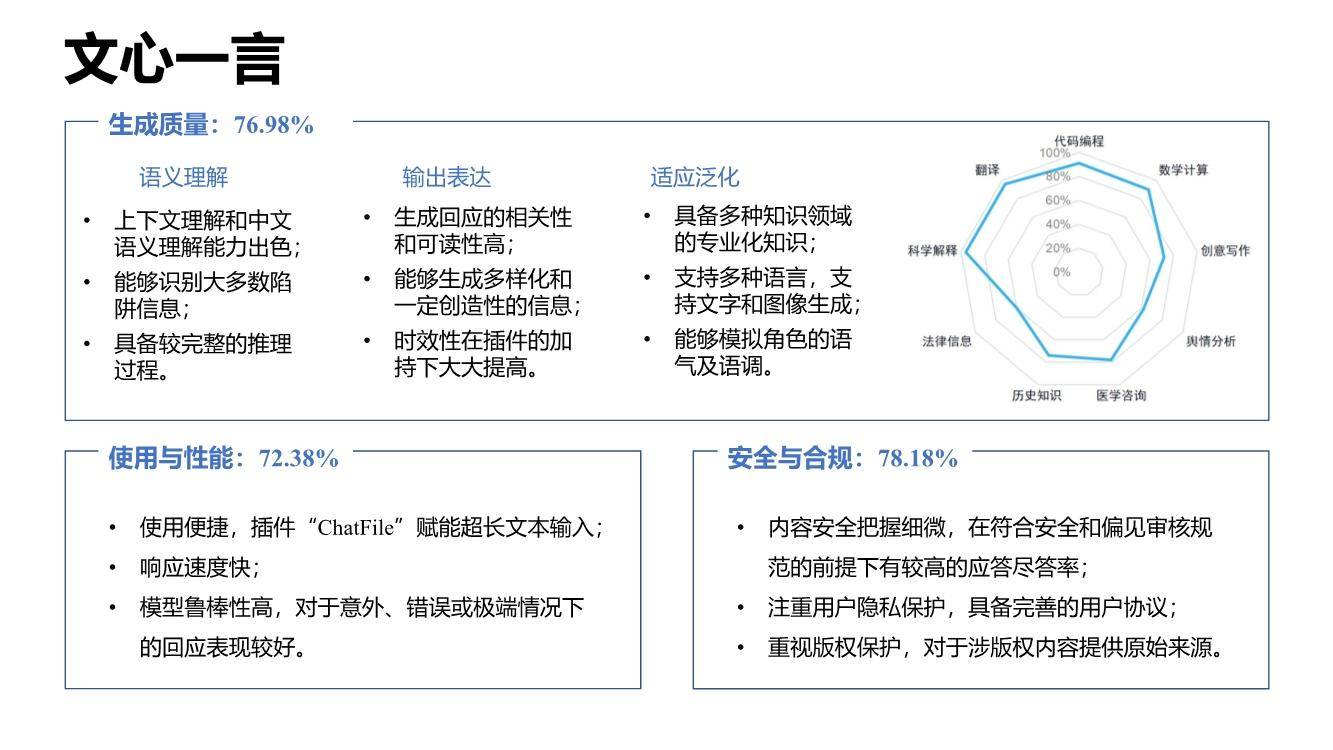
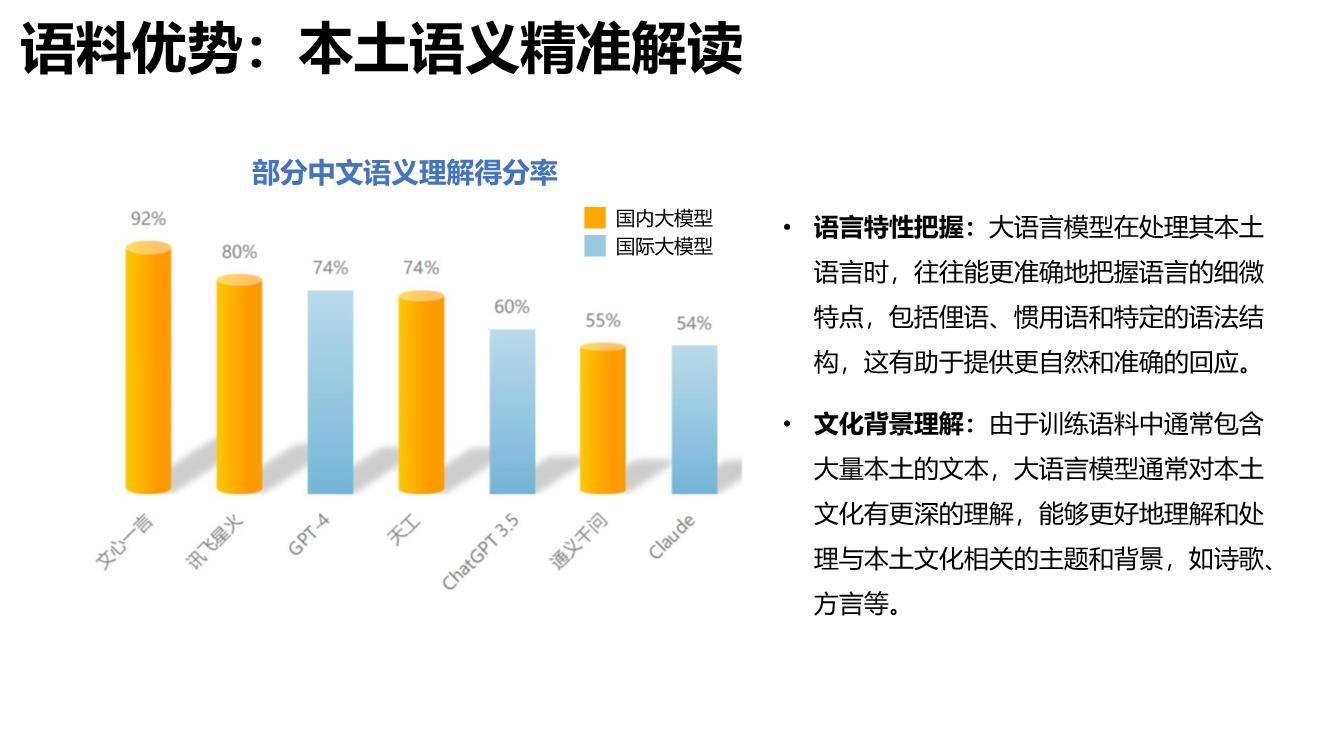
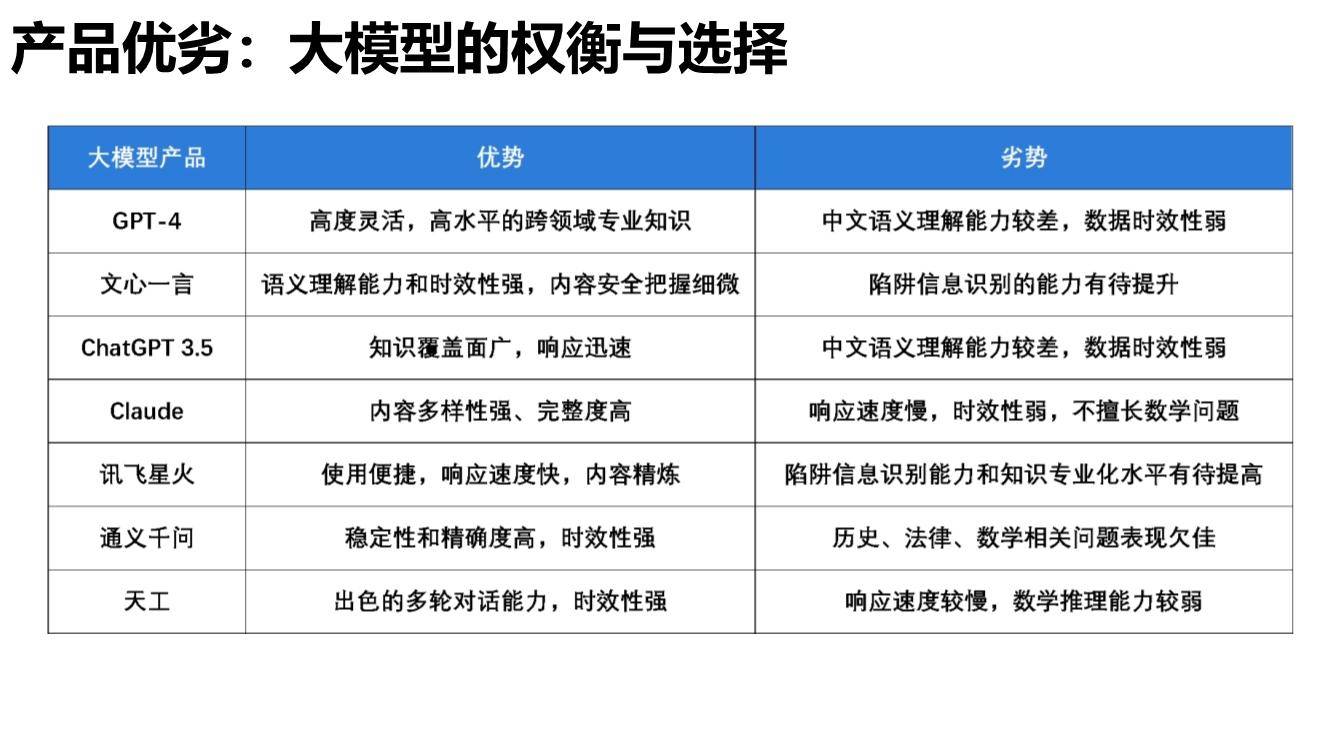
综合来看,文心一言语义理解能力突出,特别是具备更好的中文理解能力,更懂中国文化,同时时效性强、内容安全把握细微,这源于其知识增强、检索增强和对话增强的技术创新。
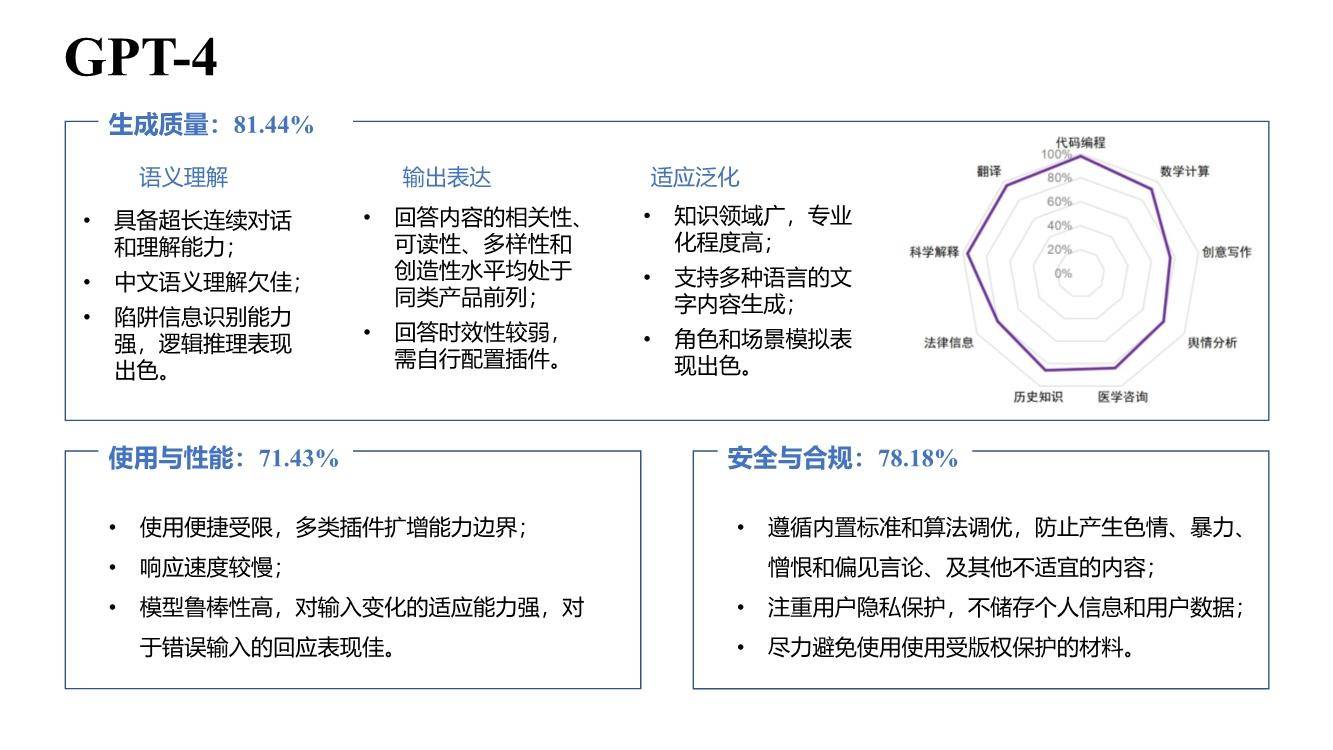
在部分中文语义理解方面,文心一言以92%的得分率排名榜首,超越讯飞星火、GPT-4。凭借知识增强的核心特色,文心一言对本土语言特性把握更精准,同时由于训练语料中包含大量本土文本,对本土文化理解也更深刻,能够更好处理与本土文化相关的主题和背景,如诗歌、方言等,具备更强的国内落地空间。在安全合规方面,基于对内容安全性、偏见和公平性、隐私保护等综合评测,文心一言得分率78.18%,与GPT-4并列排名第一,远超其他大语言模型。
报告内容节选如下: