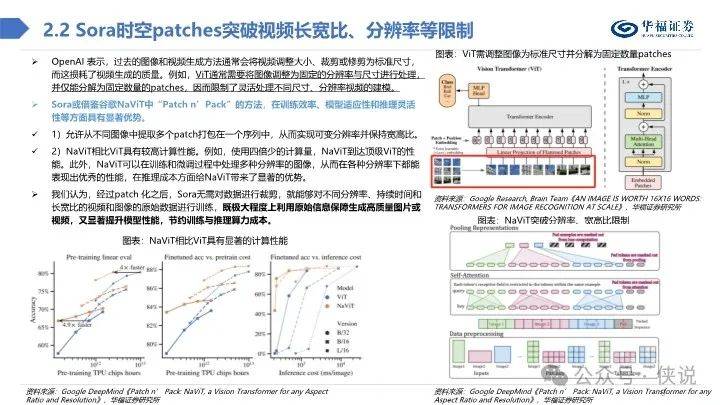
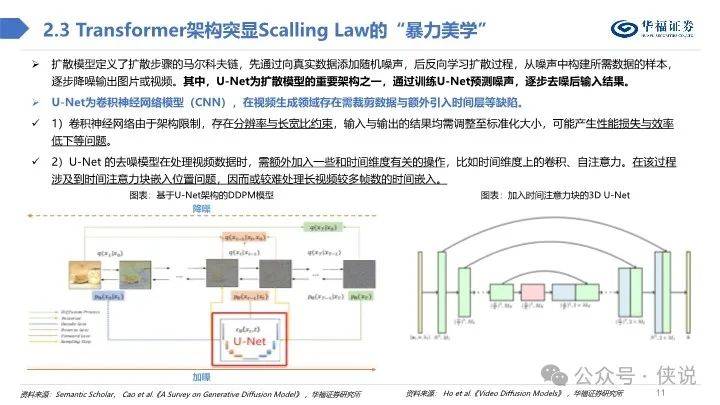
Sora技术深度解析
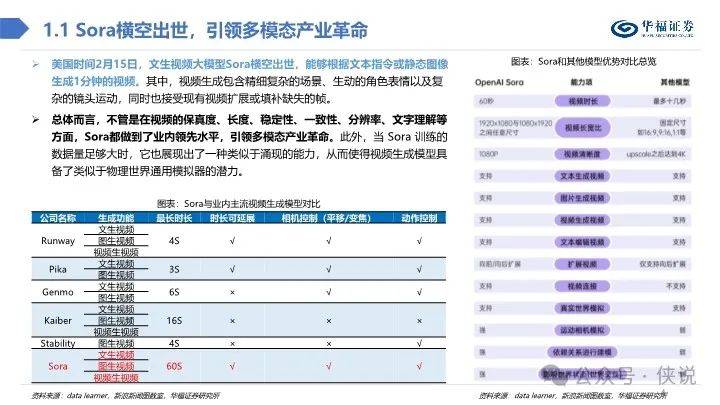
美国时间2月15日,文生视频大模型Sora横空出世,能够根据文本指令或静态图像生成1分钟的视频。其中,视频生成包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,同时也接受现有视频扩展或填补缺失的帧。
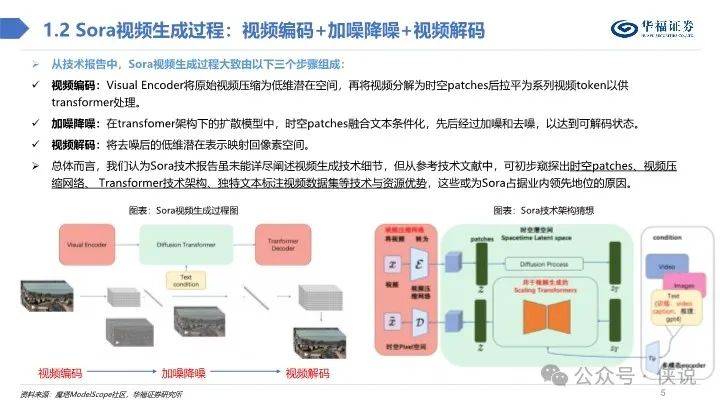
从技术报告中,Sora视频生成过程大致由以下三个步骤组成:
视频编码:Visual Encoder将原始视频压缩为低维潜在空间,再将视频分解为时空patches后拉平为系列视频token以供transformer处理。
加噪降噪:在transfomer架构下的扩散模型中,时空patches融合文本条件化,先后经过加噪和去噪,以达到可解码状态。
视频解码:将去噪后的低维潜在表示映射回像素空间。
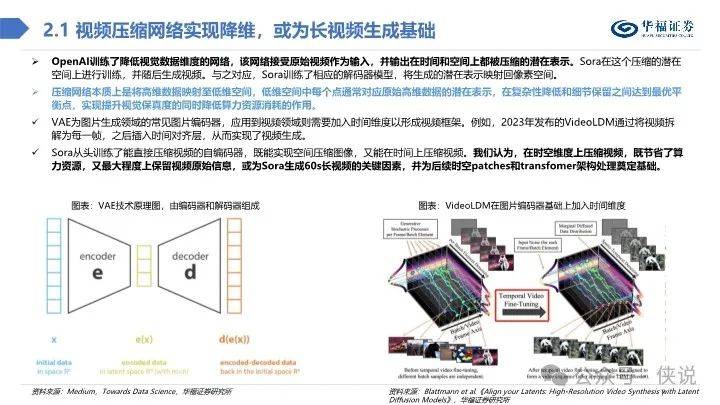
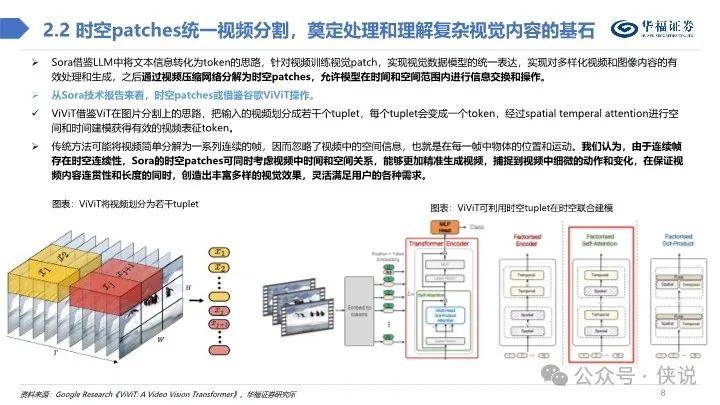
总体而言,我们认为Sora技术报告虽未能详尽阐述视频生成技术细节,但从参考技术文献中,可初步窥探出时空patches、视频压缩网络、 Transformer技术架构、独特文本标注视频数据集等技术与资源优势,这些或为Sora占据业内领先地位的原因。
报告节选内容如下: