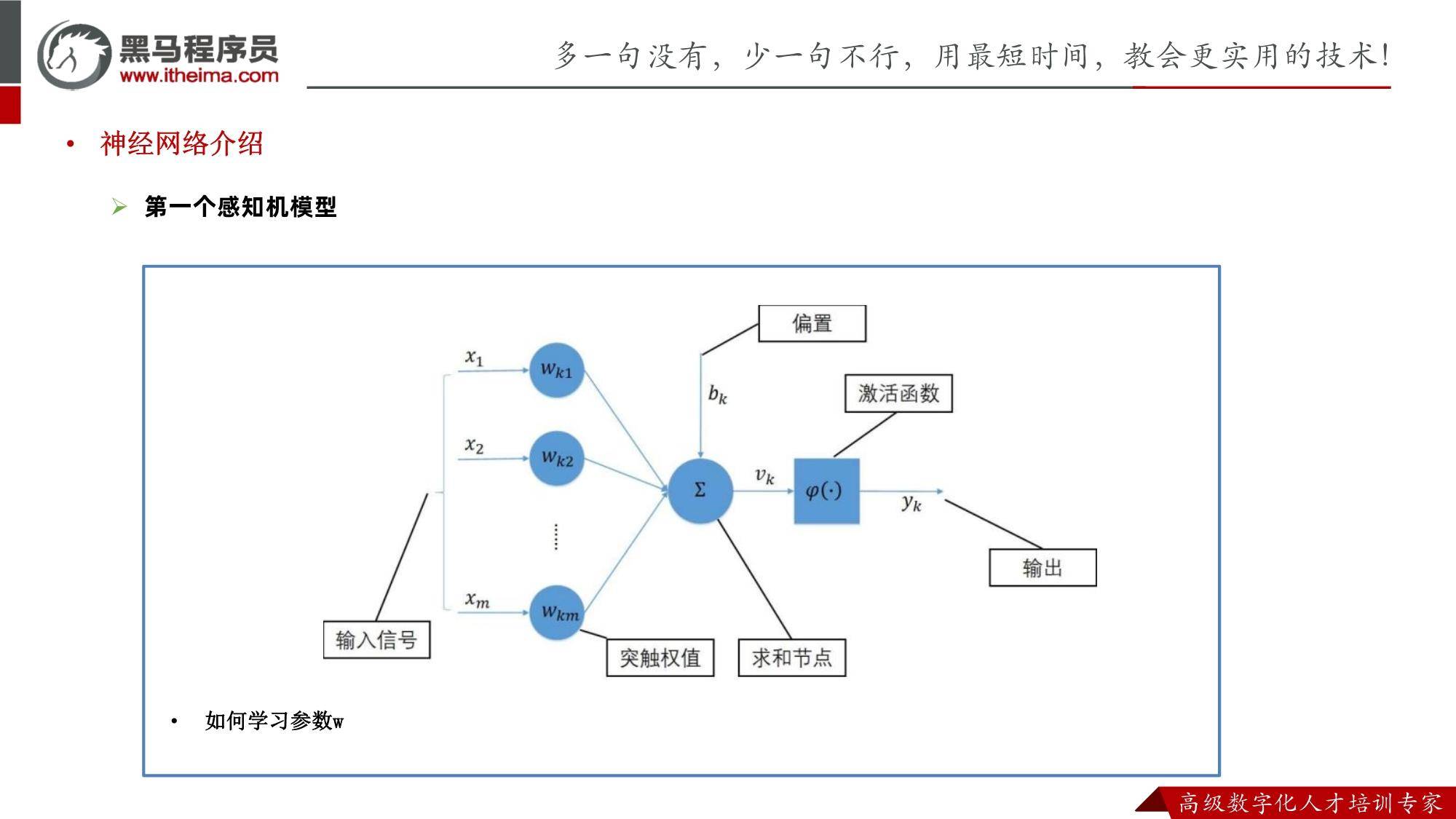
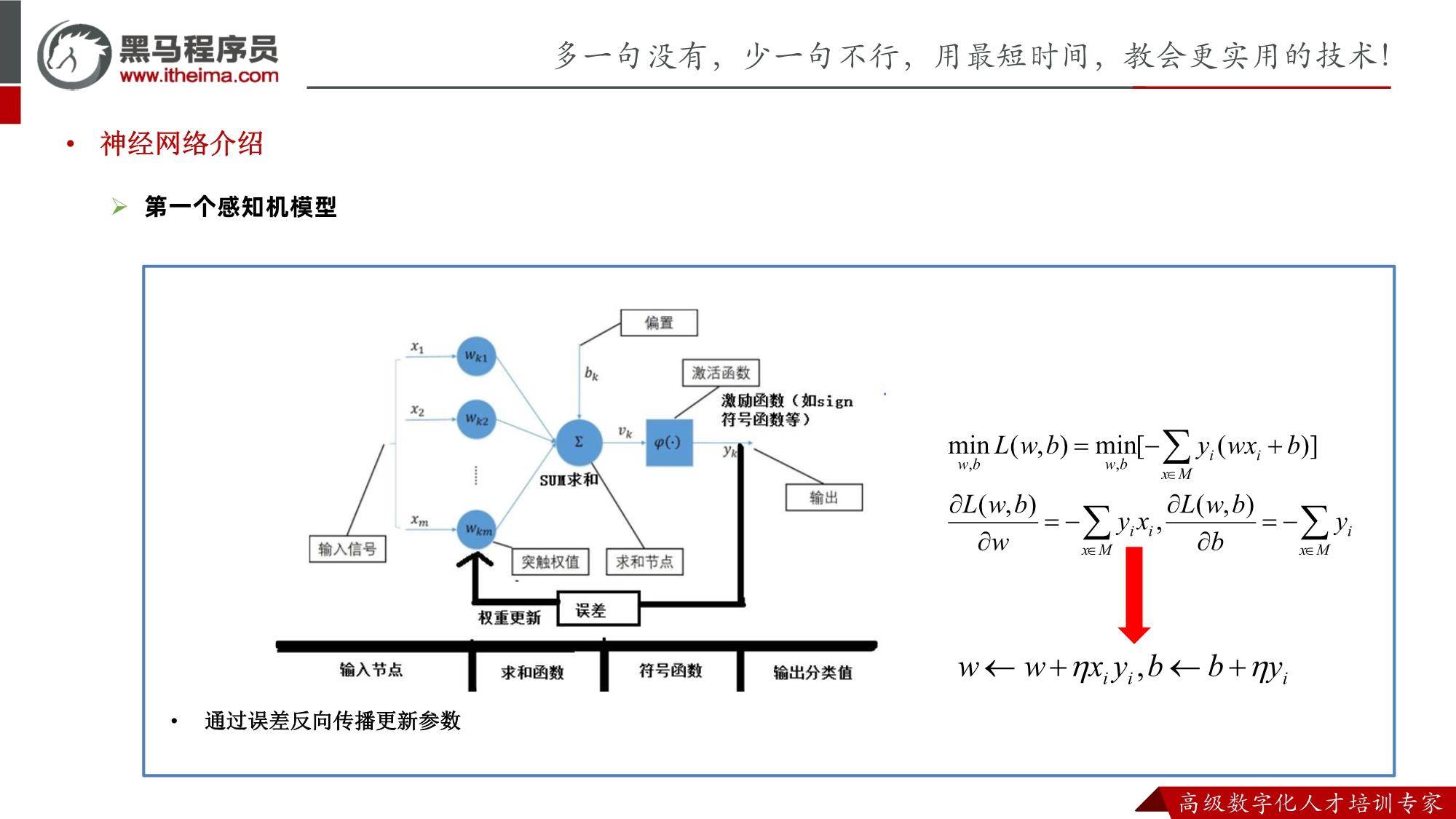
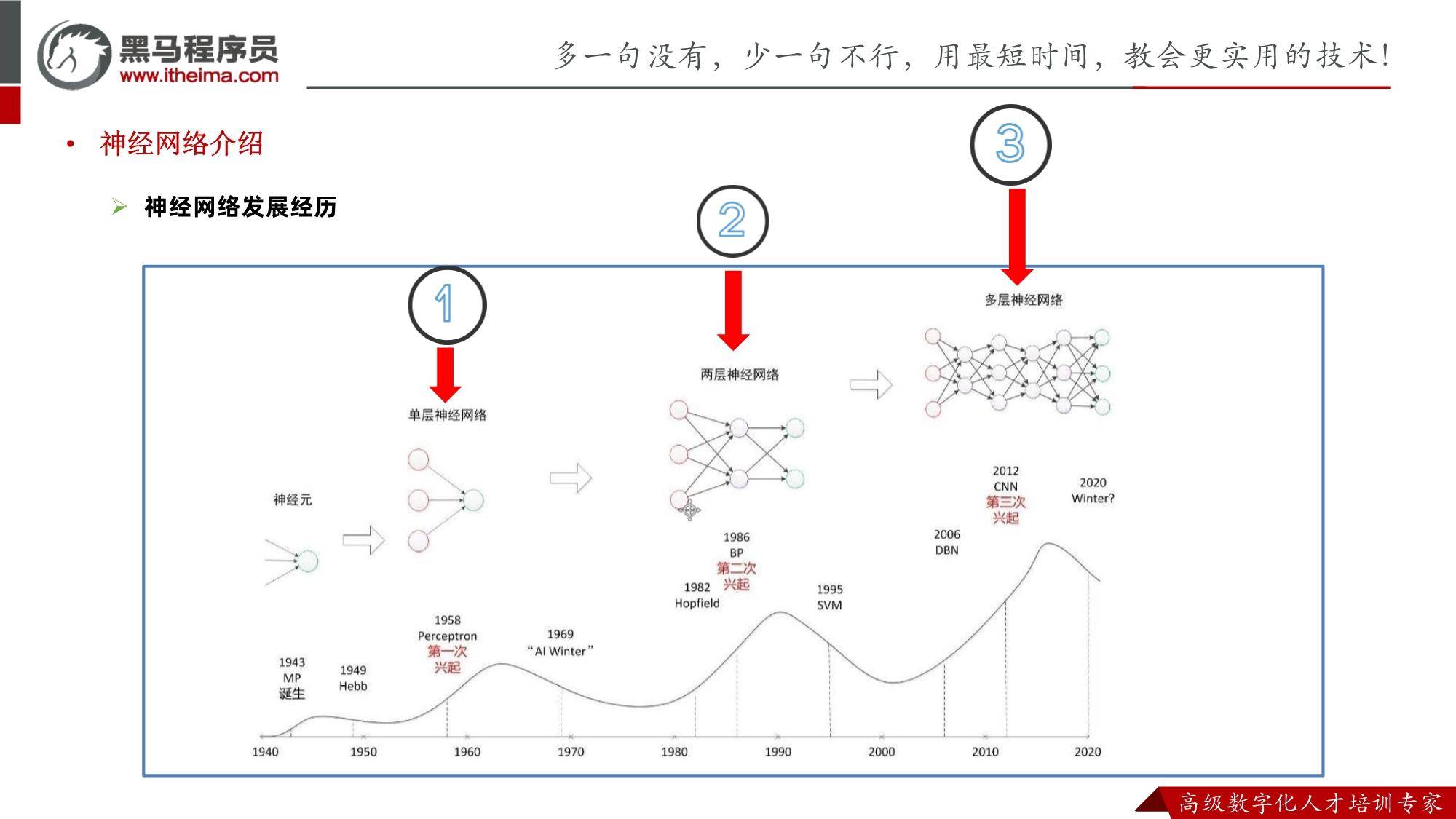
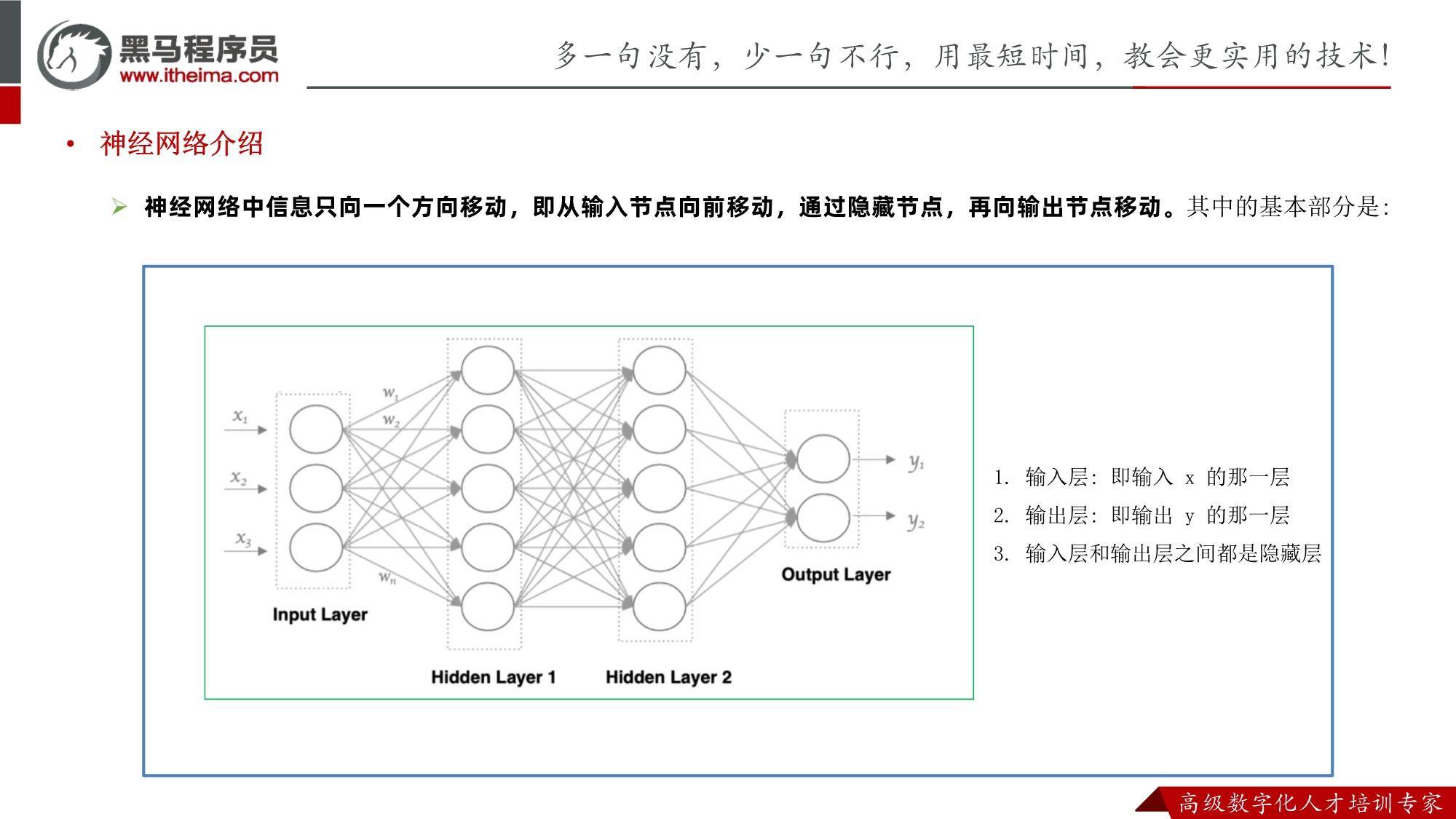
ChatGPT原理PDF:挖掘ChatGPT底层原理,理解实现方法
ChatGPT是一种基于人工智能的自然语言处理模型,是由OpenAI提出的一种基于神经网络的自然语言处理模型,其核心是使用了Transformer网络结构。ChatGPT采用了大规模的语料库进行有监督训练,通过反向传播算法不断地调整模型参数,使得模型能够根据给定的输入文本生成相应的输出文本。
ChatGPT的实现原理非常复杂,下面我们将详细介绍它的具体实现方式。
首先,ChatGPT采用了分层表示的策略,即将输入的文本分为多个层次,每个层次对应不同的语义信息。这种分层表示的方法使得ChatGPT能够更好地理解自然语言的复杂性,并且在生成文本时能够更加准确地捕捉到上下文的语境。这种分层表示的策略被称为“自注意力机制”,通过这种机制,ChatGPT能够对自身在输入序列中的所有位置进行编码,从而使得模型能够有效地理解输入序列中不同位置之间的关系。
其次,ChatGPT采用了Transformer网络结构。Transformer是一种自注意力机制的序列到序列模型,它在自然语言处理领域中取得了非常好的效果。Transformer网络结构的核心是自注意力机制,该机制能够使模型在计算每个位置的表示时,考虑到所有其他位置的信息。这种机制可以使模型更好地理解文本中的上下文关系,并且能够捕捉到文本中的长期依赖关系。在ChatGPT中,Transformer网络结构的每个编码器层都包含了一个自注意力机制和一个全连接前馈神经网络。这些编码器层共同构成了ChatGPT的基本框架。
然后,ChatGPT采用了预训练和微调的方法进行训练。预训练是指在大规模语料库上进行无监督的训练,目的是使得模型能够学习到丰富的语言知识。在ChatGPT的预训练阶段,模型主要通过掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两种任务进行训练。掩码语言模型的任务是在文本中随机掩盖一些单词,让模型去预测这些被掩盖的单词,以此来提高模型对上下文的理解能力。下一句预测的任务是判断两个句子是否连在ChatGPT的微调阶段,模型会在特定的任务上进行有监督的训练,以进一步提高模型的性能。例如,可以在对话生成任务或者文本分类任务上进行微调,使得模型能够更加准确地生成语言或者进行分类。
最后,ChatGPT的实现原理还包括对数据的处理和模型的优化。对于数据的处理,ChatGPT采用了标记化的方法,将文本转化为一系列的标记或者词向量,使得模型能够更好地处理文本。对于模型的优化,ChatGPT采用了一系列的技术,例如Dropout、Layer Normalization等,以减少模型的过拟合,并提高模型的训练速度和性能。
总的来说,ChatGPT的实现原理包括分层表示的策略、Transformer网络结构、预训练和微调的方法、数据处理和模型优化等多个方面。通过这些技术的应用,ChatGPT能够有效地理解自然语言文本,并生成高质量的自然语言文本。ChatGPT在自然语言处理领域具有广泛的应用,例如对话生成、文本分类、语言翻译等任务,有望在未来进一步推动人工智能技术的发展。
来源:黑马程序员
报告内容节选如下: