华为诺亚方舟实验室首席科学家刘群教授谈ChatGPT技术
当业界几乎把所有的目光都聚焦到ChatGPT上,原本有些克制的科技大厂突然有了紧迫感,纷纷在类ChatGPT产品中证明自己的实力。一时间,数百亿、千亿乃至万亿级参数规模的人工智能大模型(下面简称“大模型”)相继涌现,这场ChatGPT引发的全球大模型竞赛趋于白热化。
“有大模型的企业能做ChatGPT,没有的则是在蹭热点。”对于互联网公司蜂拥扎堆做ChatGPT,阿里达摩院M6大模型前带头人杨红霞言辞犀利地说。在她看来,只有参数规模100亿以上的大模型才有实力提供高质量的对答。
百度、阿里已有比肩ChatGPT的大模型
大模型的核心特征是模型参数多、训练数据量大。有研究估测,训练1750亿参数语言大模型GPT-3,需要上万个CPU/GPU24小时不间断地输入数据。其能耗相当于开车往返于地球和月球,一次运算就要花费450万美元。高昂的研发成本意味着,主流的大模型只能由大型科技公司或少数研究机构掌握。
据了解,ChatGPT是基于8000亿个单词的语料库,包含了1750亿个参数。前者是ChatGPT的训练数据,后者是它从这些训练数据中所学习、沉淀下来的内容。这种海量参数规模让ChatGPT能够捕获更复杂的语言模式和关系,从而提高复杂自然语言处理任务的准确性。
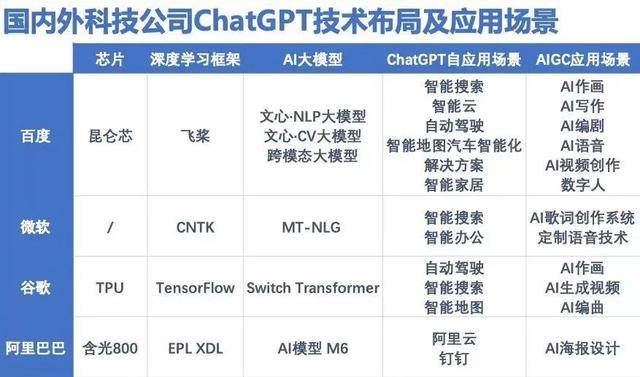
从参数规模来看,国内已经诞生了能够比肩ChatGPT参数量的大模型。百度既有20多万企业用户的飞桨平台,也有2600亿参数量的文心大模型;阿里巴巴有“通义”大模型,多模态大模型M6的参数规模已经突破10万亿,规模远超谷歌、微软,成为全球最大的AI预训练模型。OpenAI前政策主管JackClark公开点评阿里巴巴:“这个模型的规模和设计都非常惊人,是众多中国AI研究组织逐渐发展壮大的一种表现。”
当参数规模迅速攀升至几百亿、千亿时,大模型的训练方式也出现了分野。有业内专家认为,参数数量并不代表模型结果,更为关键的是训练方式。在华为诺亚方舟实验室语音语义首席科学家刘群看来,虽然我们训练了几千亿或者几万亿的数据,但训练的充分程度仍远远不够。
来源:刘群教授
号外:太侠新项目AIGC智能创作助手上线,可搜索小程序“AI方案鸭”体验,新用户赠送20次和5次AI绘画。
报告内容节选如下:






















