中国数据库行业分析报告:向量启航,引擎加持
向量数据库是专门为处理向量嵌入独特结构而构建的数据库系统。它们通过比较值并找到彼此最相似的向量来索引向量,以便于搜索和检索。
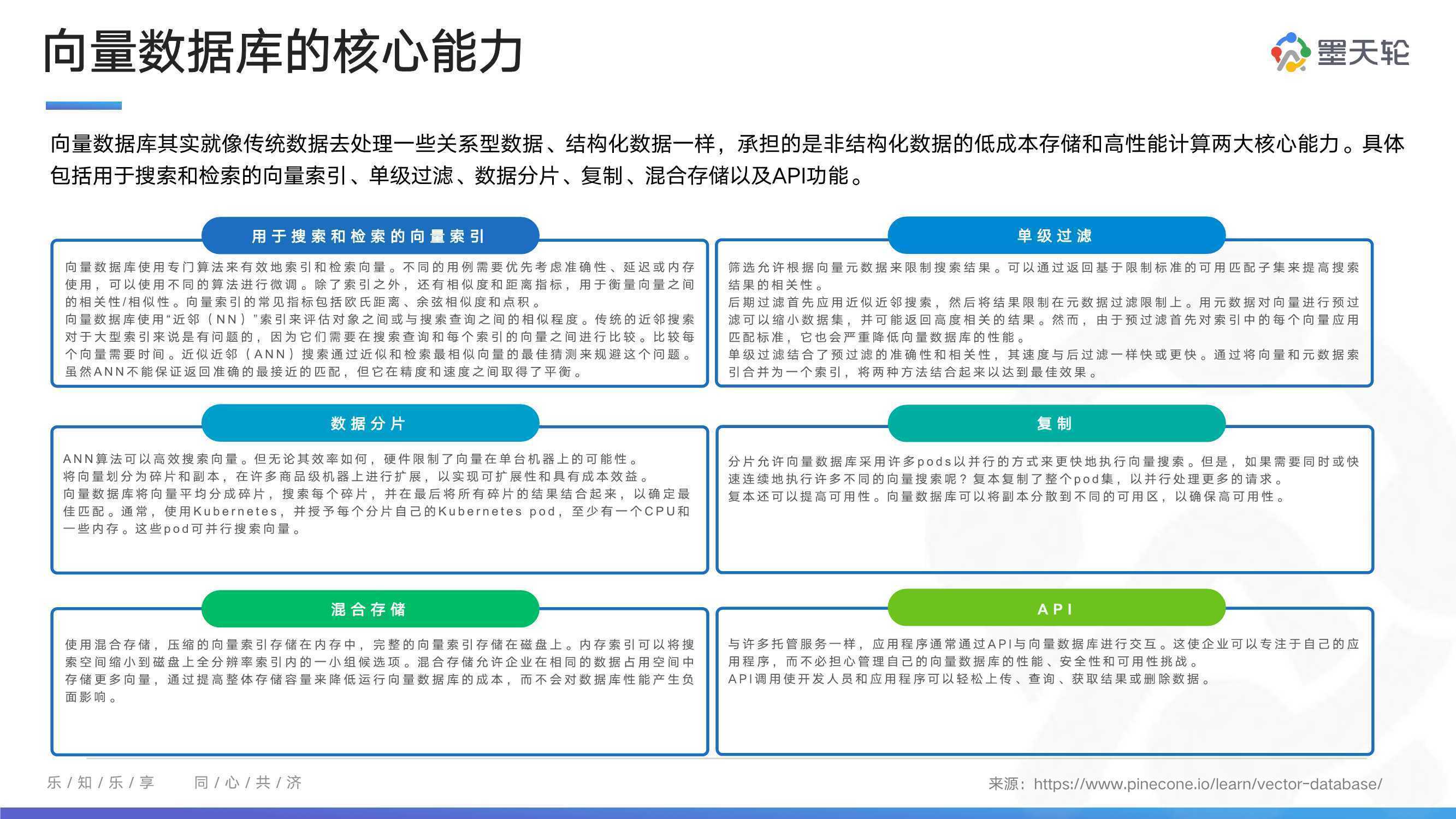
从技术角度来讲,向量数据库主要解决2个问题,一个是高效的检索,另一个是高效的分析。向量数据库其实就像传统数据去处理一些关系型数据、结构化数据一样,承担的是非结构化数据的低成本存储和高性能计算两大核心能力。
具体包括用于搜索和检索的向量索引、单级过滤、数据分片、复制、混合存储以及API功能。向量数据库主要的应用领域如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索等。
随着AI技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了AI技术链路中不可或缺的一环,更是对传统搜索技术的补充,并且具备多模态搜索的能力。
随着数据库软硬件技术的发展,经典的SQL计算引擎逐渐成为数据库系统的性能瓶颈,尤其是对于涉及到大量计算的OLAP场景。如何充分发挥底层硬件的能力,提升数据库系统的性能,成为近年来数据库领域的热门研究方向,而向量化执行就是解决上述问题的一种有效手段。
火山模型的诞生为缓存数据库的内存压力,但该设计并未充分利用CPU的执行效率且以往的火山模型一次处理一个元组的方式造成过大的解释执行代价,阻止了对性能影响极大的编译优化。
2005年《MonetDB/X100: Hyper-Pipelining Query Execution》的论文首次提出“向量化引擎”的概念,后续国产数据库陆续推出向量化执行引擎,加速OLAP场景的查询分析速度。
来源:墨天轮
报告内容节选如下: